
Statistics for Product Managers: Why Your Data May Be Lying
That 60% survey result is meaningless without the margin of error
 By Tristan Kromer·
By Tristan Kromer·Quick Answer: As product managers, we need to pair qualitative insights with properly understood quantitative data — not just glance at numbers. A 60% survey result is meaningless without knowing the margin of error, which depends on sample size, confidence level, and population size. Most product managers misuse statistics by drawing conclusions from too-small samples or biased surveys. Use tools like an Experiment Calculator, design S.M.A.R.T. experiments with clear hypotheses, and ensure your sample sizes are large enough to actually support the decisions you’re making.
By Tristan Kromer In product management, there’s a tug-of-war. At one end, our seasoned intuition, honed through years of talking to customers, observation, and user experience testing. And at the opposite end? Data. Our job, as product managers, is not simply to navigate the product landscape with our wits and a bit of luck. Our job is to bring our entire team along for the journey together. It is not enough that we know what to do, we need to draw a map for the others in our team to follow and better yet, leave clear waypoints for the next product manager to follow. Yes, we need to tell the qualitative story of the ideal customer experience. We need to guide, inform, and ultimately inspire. But we also need KPIs and validate our gut instinct with data. Sadly, many product managers do look at data - but misunderstand what they are seeing. They look at 16% conversion as better than 15%, but don’t think to check the Margin of Error to make sure the Sample Size was large enough to draw a conclusion. They don’t understand statistics and therefore don’t truly understand the uncertainty in numbers. The result is that many product managers can pitch the vision, but are ultimately navigating without a map or compass… straight into a ditch. 
The Quantitative Data Imperative
Let’s face it. Nowadays, when market dynamics shift overnight and user preferences can be as unpredictable as the next TikTok craze, qualitative narratives require quantitative data to back them up. Here’s why quantitative data is a non-negotiable in our toolkit:
- Eliminate Bias: When one person makes a decision alone, they always have assumptions that can cloud their judgment. That’s just being human, we’re fallible. Data acts as a safety net, guiding us to make informed choices with reduced risks.
- Unified Team Direction: Data resolves disputes. Can’t make a decision? Run an experiment. When our teams are equipped with numbers and trends, it eliminates ambiguity, ensuring everyone is rowing in the same direction with confidence.
- Mapping the Unknown: In uncharted product territories, it’s data that can light up our path, highlighting potential pitfalls or opportunities we might overlook.
- Benchmarking and Progress Tracking: Numbers give us milestones. They show us where we’ve been, where we’re heading, and the pace at which we’re moving.
- Fostering Stakeholder Trust: When we present our strategies backed by solid data, it builds confidence among stakeholders.
Quantitative data is not just numbers for the sake of having numbers. It’s about giving our product narratives a solid foundation, ensuring our stories are not just compelling but grounded in reality. To that end, product managers can use experiments to get data and make better decisions. Two of the most common quantitative are surveys and A/B tests.
Surveys: How to Fool Yourself
Surveys often get a bad rap, dismissed as mere questionnaires or tick-box exercises. I have personally stood on stage and told thousands of entrepreneurs to never, ever, under any circumstances, run surveys. And I stand by that! 99.9% of product managers should not run surveys. I just don’t say 99.9% out loud because everyone always thinks they are part of the 0.1% that can run a great survey. Nope…most surveys, even from people who claim to be great at surveys, are terrible. Surveys are not inherently bad. They seem simple, but are actually quite hard to do well. Like playing the guitar. It’s easy to learn three chords and butcher Guns n Roses, but a masterpiece like Playing God by Polyphia or Mediterranean Sun Dance by Paco De Lucia, Al Di Meola and John McLaughlin is beyond most mortals. However, surveys can be a versatile and direct feedback tool with a little practice and statistical knowledge. User Feedback Surveys can provide a direct line to our user’s minds. Their pains, their preferences, the nuances that might escape even the most observant product manager. With the variety of SaaS survey tools available, we can easily run and update surveys in minutes, getting insights in hours rather than weeks. Want to gauge satisfaction on a recently launched feature? Or perhaps, test the waters for a radical new idea? Surveys can be tailored to capture just about any kind of feedback. While we should always start with customer interviews and user observations - those methods can’t give us an overall picture of trends. But we can take our deep insights from interviews and run large scale surveys to see if our observations hold up at scale. Let’s look at an example, how it can go wrong, and how we can fix it.
Example: Gauging Interest for a New Product
Let’s imagine we’re working at a new innovative insurance company based in the heart of silicon valley. Your product, selling health insurance for pets, is doing great. However, your CEO just returned from their ayahuasca retreat with a brilliant new idea - AI avatars for pets. When Fido passes into doggie heaven, you can still play digital fetch with an AI Fido replicant. The CEO, knowing that his investors will balk at this big change of direction, runs a survey asking the simple question: “Would you rather have an insurance policy for your dog or pay the same price for a digital avatar of your dog so they will live forever as an AI?” The results come back and 60% of our customers say they would prefer DigiDog - the AI programmable pooch.  Should you pivot? The CEO certainly thinks so and the “reality distortion field” is kicking in…everyone is excited. It’s tempting to view that 60% result as a siren song, beckoning us into the comforting embrace of DigiDog’s digital fur. However, there are some basic problems here.
Should you pivot? The CEO certainly thinks so and the “reality distortion field” is kicking in…everyone is excited. It’s tempting to view that 60% result as a siren song, beckoning us into the comforting embrace of DigiDog’s digital fur. However, there are some basic problems here.
The Question’s Bias
The question presented to our customers was essentially asking: “Would you rather insure against the sad reality of doggie demise OR ensure that your beloved pet will ‘live’ forever?” The wording itself is emotionally loaded, priming participants to lean into the comforting foreverness of DigiDog. Then there’s the bad sampling. If the CEO only surveyed people on their trip (pun intended), then they may only be surveying like minded people who agree with them. Not a representative sample of the whole population. In short, we can ruin our quantitative data by creating biases in the survey design.
Statistics Problems
But even if we set aside these issues and design the perfect, non-biased survey with a perfect sampling process, there is a fundamental statistics problem here in that the CEO doesn’t know statistics. 60% is not a valid result for any survey unless it also includes the margin of error. At this point, you may be thinking, “Dear god we’re going to do math.” Fear not! We’re going to skip most of the math parts of statistics here and we have a handy Experiment Calculator (which you’ll see in action below.). So you don’t actually have to do any math. But you do need to know what numbers to put into the calculator.
Scary Statistics Terminology
If you’re not familiar with the terms, please read on about:
- Margin of Error
- Confidence Level
- Population Size
- Sample Size
If you already know, you can scroll down to the section on experiments.
What is Margin of Error?
Margin of Error (MoE) is like the uncertainty buffer around our survey results. Our CEO reported a 60% preference for DigiDog. However, we don’t know the actual percentage. If we surveyed everyone in our target audience, we would have an exact picture and 60% would truly be 60%. But if we surveyed a small number of people, our results may be completely off. At the extreme, imagine that we survey just 1 person. If they are excited about Digidog and give us their credit card, that’s a result of 100%. Does that mean 100% of people will purchase our product? No. It just means that the % of people who will purchase our product is not zero. The Margin of Error is HUGE. If we sample two people, our Margin of Error will get smaller and we’ll have a better picture. The more people, the smaller the Margin of Error in our survey. The formula is: 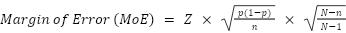 Z is the Z-score (which corresponds to the desired confidence level). p is the result. N is the population size. n is the sample size. So we need to know the Confidence Level, the Population Size, and the Sample Size to calculate the Margin of Error and then we can actually understand what the CEO’s survey actually means.
Z is the Z-score (which corresponds to the desired confidence level). p is the result. N is the population size. n is the sample size. So we need to know the Confidence Level, the Population Size, and the Sample Size to calculate the Margin of Error and then we can actually understand what the CEO’s survey actually means.
What is the Confidence Level?
The confidence level gives us a measure of certainty about our survey results. Think of it as a safety net for your data. If we claim a 95% confidence level, it means that if we were to run the same survey 100 times, we would expect the results to fall within our specified margin of error 95 times out of those 100. It essentially communicates: “We’re 95% certain that the actual result (in the entire population) is within the margin of error of our reported result.” For instance, imagine we’re trying to estimate the average amount our users spend on pet health care by measuring the spend of a few users. If we claim a 95% confidence level, it means we’re 95% sure that the average amount spent on pet health care is within a certain range. While there are various confidence levels we could choose from, like 90%, 99%, or others, in most scenarios, statisticians recommend a 95% confidence level as a good balance between accuracy and practicality. However, in entrepreneurial decisions where we are prepared to take a lot more risk than the average statistician, it is absolutely possible to choose something lower. For the sake of our discussions and the DigiDog dilemma, we’ll stick with the tried and true 95% confidence level.
What is Population Size?
For our survey, this is just the size of the actual target customers. So if we are interested in the views of the typical American customer, the population is about 330,000,000. However, not all of those people are dog owners. So it’s significantly smaller but we might not know the exact number. Fortunately, if the population is fairly large, it doesn’t matter all that much and it doesn’t change the equation. So as a rule of thumb, if the population is over 200,000 you can just enter any number larger than that and it won’t change the Sample Size you need to get the same Margin of Error. (See graph) Here’s a calculation of the recommended sample size: It’s interactive - try removing zeros from the population until you start to see the recommended sample size change. It has to get pretty low to see any difference! 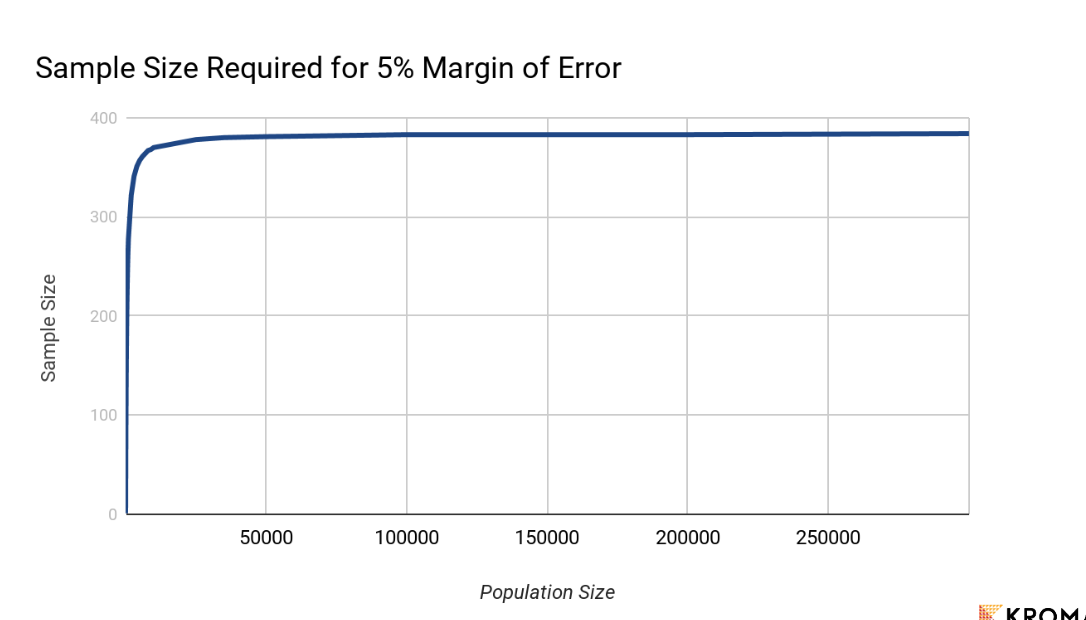
What is Sample Size?
When you are at the ice cream counter and ask for a sample of secret breakfast ice cream, you get a little scoop. The sample size is just the size of the spoon. If you have a teaspoon, you’ll get a pretty good idea of the ice cream flavor. If the spoon is too small, you’re not getting enough to make a judgment. Just as the size of the ice cream scoop determines how well you can judge the flavor, the number of customers surveyed determines how accurately we can judge their preferences. The sample is a subset of our entire customer base or population. The bigger the sample size, the more accurate and reliable our results will be – up to a point. After a certain threshold, increasing the sample size offers diminishing returns in terms of increased accuracy. (See the graph.) 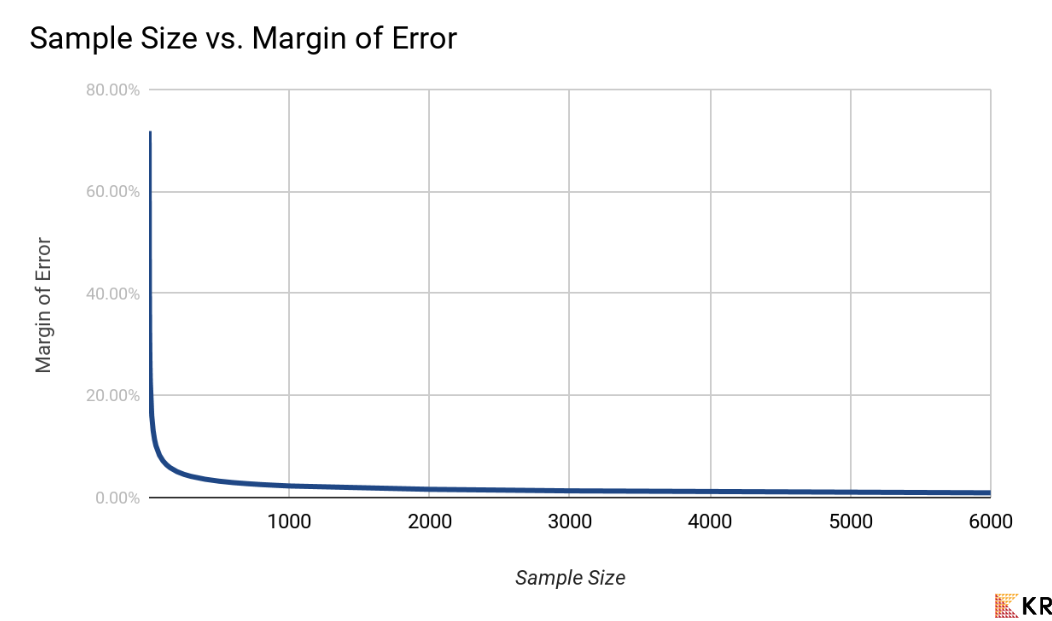 If our innovative insurance company has, say, 100,000 customers but the CEO only surveyed 20 people, the MoE will be 22.93%. That means the 60% who liked Digidog could actually be as low as 37.07% in the total population. What you see above is Kromatic’s interactive experiment calculator. So try it now, change the sample size on both DigiDog and Insurance and see the Margin of Error increase or decrease. Our CEO, while potentially having a brilliant idea, may have surveyed only a handful of people, skewing the results and leading us down a perilous path.
If our innovative insurance company has, say, 100,000 customers but the CEO only surveyed 20 people, the MoE will be 22.93%. That means the 60% who liked Digidog could actually be as low as 37.07% in the total population. What you see above is Kromatic’s interactive experiment calculator. So try it now, change the sample size on both DigiDog and Insurance and see the Margin of Error increase or decrease. Our CEO, while potentially having a brilliant idea, may have surveyed only a handful of people, skewing the results and leading us down a perilous path.
Run a Better Experiment
The answer, of course, is to run a better survey with fewer built-in biases and a bigger sample size. (Yes, Kromatic has a whole program on Running Better Experiments and a module on Effective Survey Design.) Based on the results so far, we could target a Margin of Error of 7% and we could recommend a sample size of at least 196 people. But try it out yourself! Change the Target Margin of Error in the calculator above and see how the suggested sample size changes.
A/B Tests: The Judge & Jury of Silicon Valley
Everything about Sample Size and Margin of Error applies directly to A/B tests as well. This is one of the most common forms of testing for high scale Silicon Valley startups which can run tests with thousands or millions of users. (Google famously ran a A/B/C/D…etc. test with 41 variations of the color blue.) Simply put, we can compare 2 (or 41) different variations of a landing page (or any product feature) directly to each other to understand which performs better. It works with shades of blue and it works great with physical products as well. Although it can be hard to control the test in the real world to eliminate other changes to the environment that might change the results. Unfortunately, while many Silicon Valley CEOs correctly run tests to make decisions, pure quantitative data doesn’t help if you’re testing the wrong thing. Most of us don’t have Google’s time, money, and user base to test every shade of blue. Instead, we need to use human judgment to make sure that we focus on testing the right thing with a clear hypothesis.
Create a Real Hypothesis
Before starting the test, you should have a clear hypothesis as to why the change we are making will make a change in user behavior. For instance, “Adding a picture of a human smiling at a digital dog to the DigiDog landing page will increase empathy and thus sales.” Without making this hypothesis (and the associated assumptions) clear, we may know which shade of blue is best, but not why. The knowledge of why humans behave the way they do allows us to better design our next tests and apply knowledge gained from one test into general principles like “put a picture of a human and dog on every page.” There are a variety of templates like the Learn S.M.A.R.T. Experiment Template to design our tests. The Learn S.M.A.R.T. Experiment Template is a structured approach to designing experiments, ensuring that they are Specific, Measurable, Achievable, Relevant, and Time-bound. This template helps in setting clear objectives and expectations for the experiment. Then once we have the results, we can use our Experiment Calculator to understand the results. Here are the results of an A/B/C test. Try adjusting the results and see how the calculator automatically tells us the winner.
Lessons Learned
At the end of the day, we have to use qualitative and quantitative data together. Silicon Valley product managers sometimes rely a bit too much on data without looking at the impact of the product on people. But it’s much more common to have product managers who quote data without actually understanding the numbers. As product managers, we need more than just instinct or a visionary CEO post-meditative experience. We need the right tools, an understanding of statistics, and the ability to critically analyze data. Because while an AI Fido that chases digital cars sounds groundbreaking, it’s essential to ensure our product decisions are based on sound experiment design and clear, unbiased data. Remember, it’s not about tossing out our qualitative insights. It’s about supporting them with quantitative foundations.
- Start with your qualitative insights and vision.
- Back up your intuition with quantitative data.
- Design S.M.A.R.T. experiments with a hypothesis.
- Learn to use an Experiment Calculator.
Special thanks to Kenny Nguyen for reviewing and giving feedback on this post.
Frequently Asked Questions
Why do product managers need to understand statistics?
As product managers, we often look at data like conversion rates without checking whether our sample size was large enough to draw valid conclusions. Understanding concepts like margin of error, confidence level, and sample size prevents us from making costly decisions based on misleading numbers. Statistics turns unreliable gut feelings into informed, defensible product decisions that our entire team can follow.
What is margin of error and why does it matter for product decisions?
Margin of error is the uncertainty buffer around survey or test results. If 60% of respondents prefer a feature but the margin of error is 23%, the true preference could be as low as 37%. Without knowing the margin of error, we can’t tell whether our data actually supports a decision. Larger sample sizes reduce the margin of error and give us more reliable results.
Why are most product surveys so bad?
Surveys seem simple but are extremely hard to execute well. Common mistakes include emotionally loaded question wording that biases responses, non-representative sampling (like only surveying people who already agree with you), and insufficient sample sizes that produce meaningless results. As product managers, we should start with customer interviews and observations first, then use surveys only to validate those qualitative insights at scale.
How do you design a good A/B test with a hypothesis?
Before running an A/B test, we need a clear hypothesis explaining why a change will affect user behavior — for example, “Adding a smiling human photo will increase empathy and thus sales.” Using a framework like the Learn S.M.A.R.T. Experiment Template ensures experiments are Specific, Measurable, Achievable, Relevant, and Time-bound. Without a hypothesis, we may learn what works but never understand why, limiting our ability to apply insights elsewhere.
How do I calculate the right sample size for a product experiment?
You need to know your desired confidence level (typically 95%), your population size, and your target margin of error. Tools like Kromatic’s Experiment Calculator handle the math for you. As a rule of thumb, if your population exceeds 200,000, population size barely affects the calculation. For a 7% margin of error at 95% confidence, you’d need at least 196 responses — far more than the handful many teams actually collect.

Comments
Loading comments…
Leave a comment