
How Many Customer Interviews Are Enough? The Pre-Testing Sweet Spot
Why 10-30 conversations beat academic rigor for founders who need answers fast
 By Tristan Kromer·
By Tristan Kromer·Quick Answer: For pre-testing business assumptions, 10 customer interviews is a workable minimum that yields useful insights, while 30 interviews effectively eliminates the statistical penalty of small sample sizes—making the 10-30 range your sweet spot. Anything fewer than 5 is hard to take seriously. As product managers, we should focus on financial significance over academic rigor: small samples let us look for big, obvious signals (like 0 out of 10 confirmations) that quickly invalidate bad assumptions, enabling a much higher experimentation velocity.
How many customer interviews are required to test unproven assumptions? (This is a guest post by Luke Szyrmer, a Product Manager and Consultant, and author of the just released Launch Tomorrow, a book on the use of paid advertising to test, launch, and promote new products. You can find Luke on Twitter, LinkedIn or his website__.)
Every block of stone has a statue inside it and it is the task of the to discover it. —Michelangelo
Your goal is to make money, not to publish peer-reviewed academic sociological research. While it’s good to use the scientific method to test out a business idea, don’t get lost in statistical minutiae. In particular, rigorous statistical analysis is a luxury that early stage founders can’t afford. 99% certainty costs a lot of time and money. As a founder, focus on financial significance, not the rigorously high bar of statistical significance to a high level of certainty In order to get financial significance, look for big and obvious winners based on smaller sample sizes. Having a small sample size introduces additional uncertainty and variation about the test, in addition to the usual level of uncertainty. Most frequently, when you are at this stage, you are trying to guess the average value of a particular characteristic among a large group of people. In statistical terms, you are using a sample to find the population mean. At a small sample size, you have additional statistical error. This error simply means that your statistical tools need more data in order to be certain of your outcome. In fact, this error is proportional to the sample size and the population mean like this: Error ~ standard deviation / (sample size)^(1/2) Here is what this means visually. If the measure value of a particular value is 0, and you want to generate a range for which you have 95% certainty of the value of the true population mean, this is how much additional variation exists purely because of the sample size: 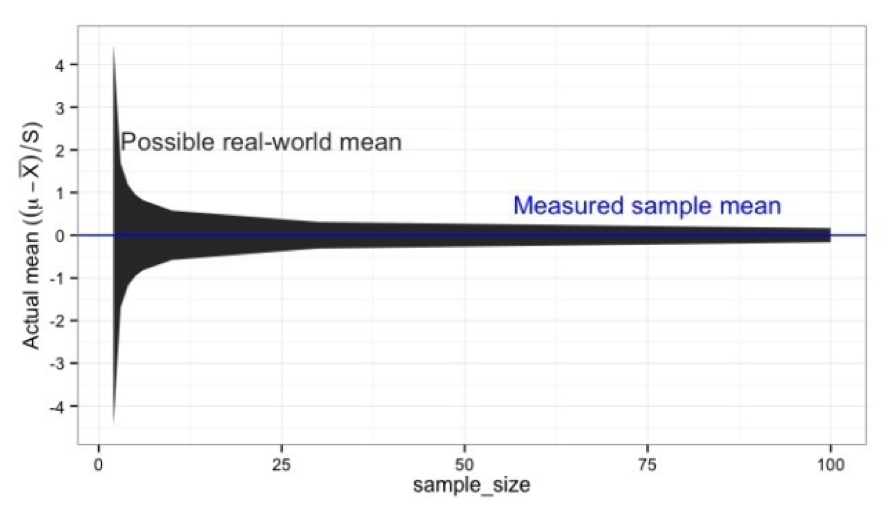
image credit: tomhopper.me
As you can see, at very low sample size the uncertainty is quite large so the question is how many customer interviews are required here? While we can’t know the population mean for certain, we do know that increasing the number of observations increases our certainty in our estimate of the true variable value. Founders frequently question “Is the sample size big enough to say something meaningful about the population?” This means that at a small sample size, you’re more likely to reject a true statement. Just because you don’t see a significant difference between the value you expect (where significance means cutoff vs. calculated sample value), it doesn’t mean that the difference isn’t there (cutoff vs. actual population value). If your number of observations is low, you are at the far left of the graph above (or its equivalent around the value in your sample). There is still a lot of statistical error around the value you’ve obtained. If the actual value does lie in the range of your estimate, you’ll still be quite uncertain as to whether or not it is actually there, purely due to your small sample size as the biggest hit is to find that how many customer interviews are required to verify your assumptions. Yet small sample sizes matter, if you can get them to work. They mean that you can achieve a much higher market test velocity, cycling through a number of tests in order to obtain conclusions faster.  Case Study: Brewing A Better Beer At the turn of the 20th century, William Gosset was a brewer working for Guinness. Trained as a mathematician and a chemist, he ended up working at the brewery because of bad eyesight. At the time, Guinness was bucking the trend of “brewing craftsmanship” in brewing beer, where master craftsmen were the primary way to ensure high quality beer was produced. Instead, Gosset started to use data science in order to analyze beer production more rigorously—in order to increase both quality and output. Since the brewery gathered lots of data on the beer being produced, Gosset needed a way to pre-qualify test ideas, in order to quickly figure out what’s worth testing at a bigger scale. He ultimately figured out, that having a small sample size was the critical component to these “pre-tests”. In order to identify the big tests worth investing in, he first executed small sample size tests to check whether it’s even likely or how many customer interviews will tell that there will be a surprising outcome. So for example, if he expected something to be true 70% of the time, before he ran a test with 1000 observations, he ran one with 10 to double check whether it held true approximately 7 times. If so, then he invested in the larger test with many observations to get actionable precision. This type of “pre-testing at small sample sizes” was revolutionary. He later calculated exactly how much additional uncertainty existed when working with small sample sizes. He published his findings as the “Student’s” distribution, which is roughly similar to a “normal distribution” with only a little more uncertainty added by a low number of observations. Based on this approach of pre-testing, he was able to invest his time and effort into larger studies that yielded useful data. If you’d like to find out more, you’ll need to refer to a statistics textbook or this khan academy video. Pre-testing has very high financial significance. A great book on pre-testing is Failure is Obsolete by Benji Rabhan. The biggest drain on your resources isn’t doing the statistical analysis; it’s usually generating the data in the first place, i.e. getting enough data. The single-most important component of getting “data” at an early stage is being able to hustle and get in front of enough prospects, in order to generate the observations in the first place. If you reduce the number of observations you require to make a decision, the cheaper and faster you’ll get to an idea that works, assuming there are detectably big differences.
Case Study: Brewing A Better Beer At the turn of the 20th century, William Gosset was a brewer working for Guinness. Trained as a mathematician and a chemist, he ended up working at the brewery because of bad eyesight. At the time, Guinness was bucking the trend of “brewing craftsmanship” in brewing beer, where master craftsmen were the primary way to ensure high quality beer was produced. Instead, Gosset started to use data science in order to analyze beer production more rigorously—in order to increase both quality and output. Since the brewery gathered lots of data on the beer being produced, Gosset needed a way to pre-qualify test ideas, in order to quickly figure out what’s worth testing at a bigger scale. He ultimately figured out, that having a small sample size was the critical component to these “pre-tests”. In order to identify the big tests worth investing in, he first executed small sample size tests to check whether it’s even likely or how many customer interviews will tell that there will be a surprising outcome. So for example, if he expected something to be true 70% of the time, before he ran a test with 1000 observations, he ran one with 10 to double check whether it held true approximately 7 times. If so, then he invested in the larger test with many observations to get actionable precision. This type of “pre-testing at small sample sizes” was revolutionary. He later calculated exactly how much additional uncertainty existed when working with small sample sizes. He published his findings as the “Student’s” distribution, which is roughly similar to a “normal distribution” with only a little more uncertainty added by a low number of observations. Based on this approach of pre-testing, he was able to invest his time and effort into larger studies that yielded useful data. If you’d like to find out more, you’ll need to refer to a statistics textbook or this khan academy video. Pre-testing has very high financial significance. A great book on pre-testing is Failure is Obsolete by Benji Rabhan. The biggest drain on your resources isn’t doing the statistical analysis; it’s usually generating the data in the first place, i.e. getting enough data. The single-most important component of getting “data” at an early stage is being able to hustle and get in front of enough prospects, in order to generate the observations in the first place. If you reduce the number of observations you require to make a decision, the cheaper and faster you’ll get to an idea that works, assuming there are detectably big differences.  When you’re at the stage of MVPs and validating your business idea (h_ow many customer interviews are required to test unproven assumptions?)_, using this pre-testing approach is very helpful to test unproven assumptions. I’ve found sample sizes of 10 very helpful when doing customer interviews, as it feels natural to think in terms of percentages, i.e. 3 out of 10 as 30%. For example, I was out with a team of friends interviewing parents of young children, in order to help identify a problem common to parents of 0-3 year olds. We set a cutoff threshold of 30% to be the criterion on whether or not they had a specific problem. We thought they were concerned with their child’s development. By interviewing 10 people, we expected to get 3 or more yes-es to confirm that we were correct. We assumed there is a standard deviation of 1. As we wanted a 95% level of certainty, that the actual value was anywhere from 10-50%. With those numbers, the level of statistical noise (error) was: Error ~ standard deviation / (sample size)^(1/2) = 1 / (10)^(1/2) = .3 So simply because we were using a sample size of 10 instead of a larger one (like 1000 in standard conversion rate optimization), we were adding an additional .3 statistical error. This increased the range from 10-50% to 7-53%. So what? These were all assumptions. In practice, we got 0 out of 10, which clearly invalidated our assumption about child development being a major concern was wrong. Even using a pessimistic statistical scenario it was pretty unlikely that our assumption was correct. But the real takeaway? The statistical error at small sample sizes is good enough to still generate useful insights and learning. The ideal size of your samples can be quite small, once you’re ready to start validating something statistically. At a sample size of 30, the small sample size stops making any difference in practice. The range of statistical error gets quite small around 30 in the graph above. If you do any less than 5 independent samples, it’s hard to take the results seriously.
When you’re at the stage of MVPs and validating your business idea (h_ow many customer interviews are required to test unproven assumptions?)_, using this pre-testing approach is very helpful to test unproven assumptions. I’ve found sample sizes of 10 very helpful when doing customer interviews, as it feels natural to think in terms of percentages, i.e. 3 out of 10 as 30%. For example, I was out with a team of friends interviewing parents of young children, in order to help identify a problem common to parents of 0-3 year olds. We set a cutoff threshold of 30% to be the criterion on whether or not they had a specific problem. We thought they were concerned with their child’s development. By interviewing 10 people, we expected to get 3 or more yes-es to confirm that we were correct. We assumed there is a standard deviation of 1. As we wanted a 95% level of certainty, that the actual value was anywhere from 10-50%. With those numbers, the level of statistical noise (error) was: Error ~ standard deviation / (sample size)^(1/2) = 1 / (10)^(1/2) = .3 So simply because we were using a sample size of 10 instead of a larger one (like 1000 in standard conversion rate optimization), we were adding an additional .3 statistical error. This increased the range from 10-50% to 7-53%. So what? These were all assumptions. In practice, we got 0 out of 10, which clearly invalidated our assumption about child development being a major concern was wrong. Even using a pessimistic statistical scenario it was pretty unlikely that our assumption was correct. But the real takeaway? The statistical error at small sample sizes is good enough to still generate useful insights and learning. The ideal size of your samples can be quite small, once you’re ready to start validating something statistically. At a sample size of 30, the small sample size stops making any difference in practice. The range of statistical error gets quite small around 30 in the graph above. If you do any less than 5 independent samples, it’s hard to take the results seriously.  The range in between is your sweet spot for pre-tests. 10 is a workable number when looking for surprising results, especially when doing customer development. But stay aware that at that number there is some statistical noise. You can calculate the additional uncertainty, or just keep in mind that you want to be significantly surprised, if you are doing customer development at sample sizes that small. Small sample sizes allow you to cycle through entire tests quickly—and have a high test velocity. As you learn, you can increase the sample sizes once you can afford to take more time and acquire a large sample of prospects, in return for greater certainty in the results you get. Now get out of the building!
The range in between is your sweet spot for pre-tests. 10 is a workable number when looking for surprising results, especially when doing customer development. But stay aware that at that number there is some statistical noise. You can calculate the additional uncertainty, or just keep in mind that you want to be significantly surprised, if you are doing customer development at sample sizes that small. Small sample sizes allow you to cycle through entire tests quickly—and have a high test velocity. As you learn, you can increase the sample sizes once you can afford to take more time and acquire a large sample of prospects, in return for greater certainty in the results you get. Now get out of the building!
Frequently Asked Questions
How many customer interviews do I need to validate a business idea?
As product managers, we can generate useful insights with as few as 10 customer interviews for pre-testing assumptions, while 30 interviews effectively eliminates the statistical penalty of small sample sizes. The sweet spot for pre-tests is between 10 and 30 interviews. Anything fewer than 5 independent observations makes it hard to take results seriously.
Why are small sample sizes acceptable for customer interviews instead of large-scale research?
The goal is financial significance, not academic statistical significance. As founders, we can’t afford the time and money that 99% certainty demands. Small sample sizes let us look for big, obvious signals—like getting 0 out of 10 confirmations of an assumption—that clearly point us toward or away from an idea, enabling much faster learning cycles.
What is the pre-testing approach for customer development interviews?
Pre-testing means running a small-sample experiment (around 10 observations) before investing in a larger, more expensive study. William Gosset pioneered this at Guinness brewery—he’d test with 10 observations first to see if results roughly matched expectations before committing to 1,000-observation studies. This lets us quickly filter out bad assumptions before spending significant resources.
How much statistical error do small sample sizes add to customer interview results?
The additional error follows the formula: error ≈ standard deviation / √(sample size). For a sample of 10, this adds roughly 0.3 in error, widening your confidence range noticeably but still yielding actionable insights. By the time you reach 30 interviews, the small-sample penalty essentially disappears and results become much more precise.
What’s the biggest bottleneck in early-stage customer validation?
The biggest drain on resources isn’t analyzing the data—it’s generating it. Getting in front of enough prospects to produce meaningful observations requires hustle. By reducing the number of interviews needed to make a decision through pre-testing, we can cycle through experiments faster and reach a viable idea more cheaply, assuming we’re looking for detectably big differences in outcomes.

Comments
Loading comments…
Leave a comment